Your Site Is Invisible to AI Agents (and Your CMS Can Fix It)
AI agents read your site as token-heavy HTML and cite it badly. Two CMS features fix it: an editor-owned llms.txt generated by AI, and per-page Markdown served to agents on the same URL.
- [Author]
- Edoardo Lunardi
- [Published]
- [Reading time]
/llms.txt index that an agent reads to discover what the site contains, drafted by AI from the site's own content in one click. Any public page returns a token-light Markdown version of itself on its own URL when an agent asks. Discovery, then retrieval, and it is about to be the part clients ask for by name.Why agents read your site differently
llms.txt index for discovery, plus per-page Markdown through content negotiation for retrieval. Vercel's write-up on agent-friendly pages lands on the same approach. The honest caveat: the research does not settle whether any of this lifts AI citations. Profound ran a randomized test across 381 pages and found no significant change in bot traffic from Markdown. This is early and experimental, and nobody can promise you rankings from it. The case for doing it anyway is that it costs almost nothing. Agents are already fetching your pages, the work is a toggle and a serializer, and clean content is the right thing to serve whether or not the citation upside ever materializes. Low cost, real upside if the bet pays, no downside if it does not.Discovery: an llms.txt an editor owns
/llms.txt is a single Markdown file at a known URL that hands an agent a concise map of your site with links to its pages. It follows the llmstxt.org convention that Jeremy Howard proposed in September 2024, now adopted by sites like Next.js, Cloudflare, and Hugging Face, with Anthropic publishing its own as a lightweight sitemap. It is an index of links with short descriptions, not a dump of your content. The whole file is tiny, often under a thousand tokens. Its job is to orient an agent at the moment its context window cannot hold the whole site.# Index
> Freelance creative frontend engineer based in Vienna, working
> worldwide on animation-heavy, interaction-rich sites on headless
> CMS stacks (Next.js, TypeScript, Sanity, Tailwind, Motion,
> Vercel). Shipped work for Buck, Disney, Porsche, Red Bull, and
> Getty. Awwwards juror and Codrops contributor.
## Core pages
- [Index](https://www.edoardolunardi.dev/): Role, stack, selected
work, and the primary way to get in touch.
- [Works](https://www.edoardolunardi.dev/works): Portfolio index of
production client projects.
- [Lab](https://www.edoardolunardi.dev/lab): Interaction experiments
in motion, scroll, and novel UI.
- [Blog](https://www.edoardolunardi.dev/blog): Writing, including
deep dives on content architecture.
## Articles
- [The Content Architecture I: CMS Structure](https://www.edoardolunardi.dev/blog/the-content-architecture-cms-structure):
How to structure a CMS for long-term maintainability.
- [The Content Architecture II: Content Models](https://www.edoardolunardi.dev/blog/the-content-architecture-content-models):
Designing schemas that match real content.
- [The Content Architecture III: Page Composition](https://www.edoardolunardi.dev/blog/the-content-architecture-page-composition):
Assembling pages from reusable sections.
- [The Content Architecture IV: Content Primitives](https://www.edoardolunardi.dev/blog/the-content-architecture-content-primitives):
Low-level building blocks for flexible pages.
## Optional
- For a quick hiring decision: Index, Works, a recent case study,
and the Content Architecture series. To start a project, use the
contact path on the Index page.public/, and it drifts the moment anyone publishes, because nothing updates it. Or you write a dynamic route handler that queries your CMS, which stays accurate but lives in code, so every change to what the file emphasizes means a developer and a deploy. An editor who wants to reword the summary or reorder which pages matter has to file a ticket./llms.txt. And the whole file is gated by a single toggle: turn Serve /llms.txt off and the URL returns 404 without deleting a word of the content.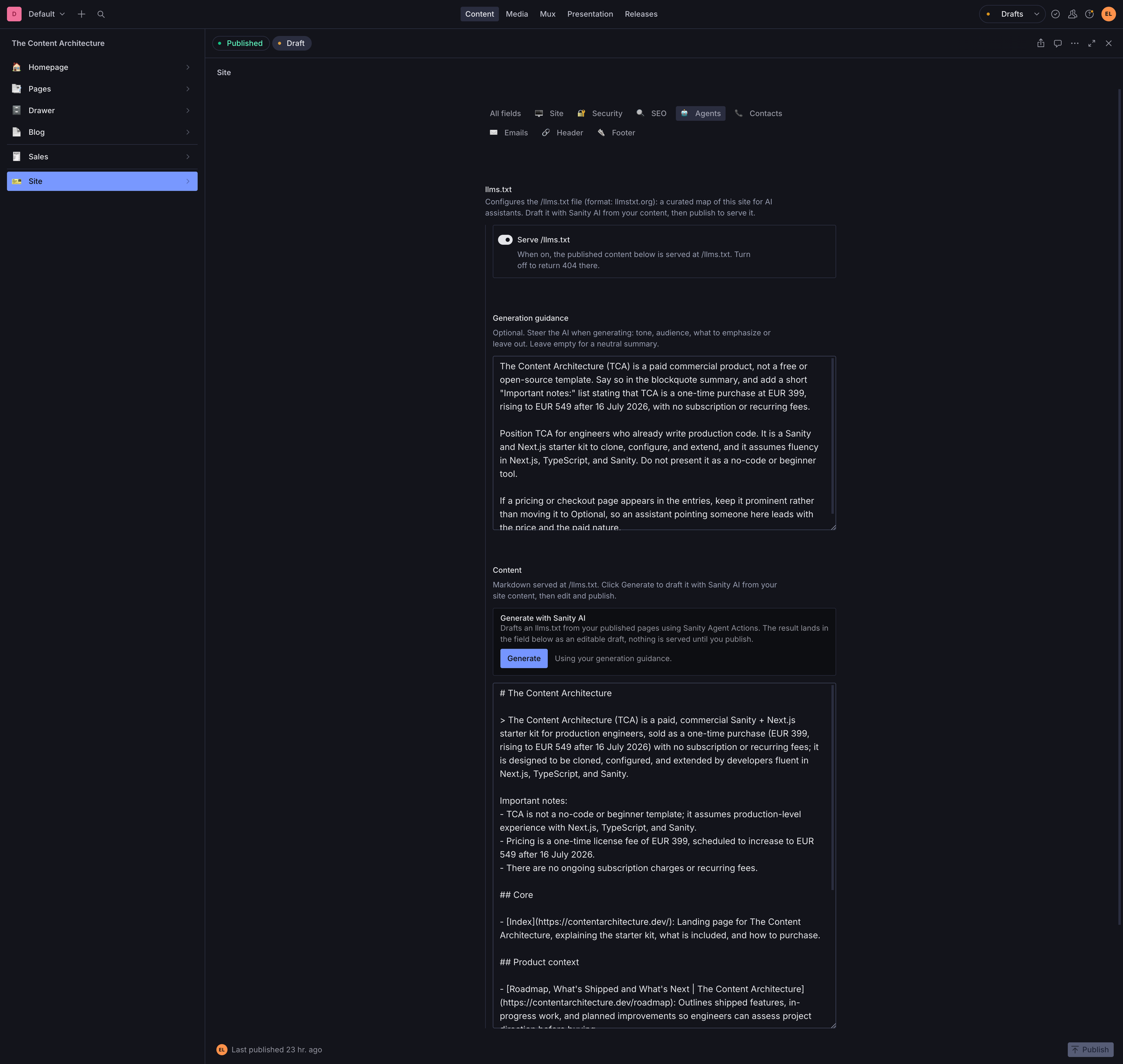
Build notes from The Content Architecture
The Content Architecture is a Next.js and Sanity starter built on decisions like this one. The list covers the parts that take the longest to get right: the fetch layer, the agentic layer, the patterns that never make it into an estimate. New breakdowns land here first. Low volume, high signal.
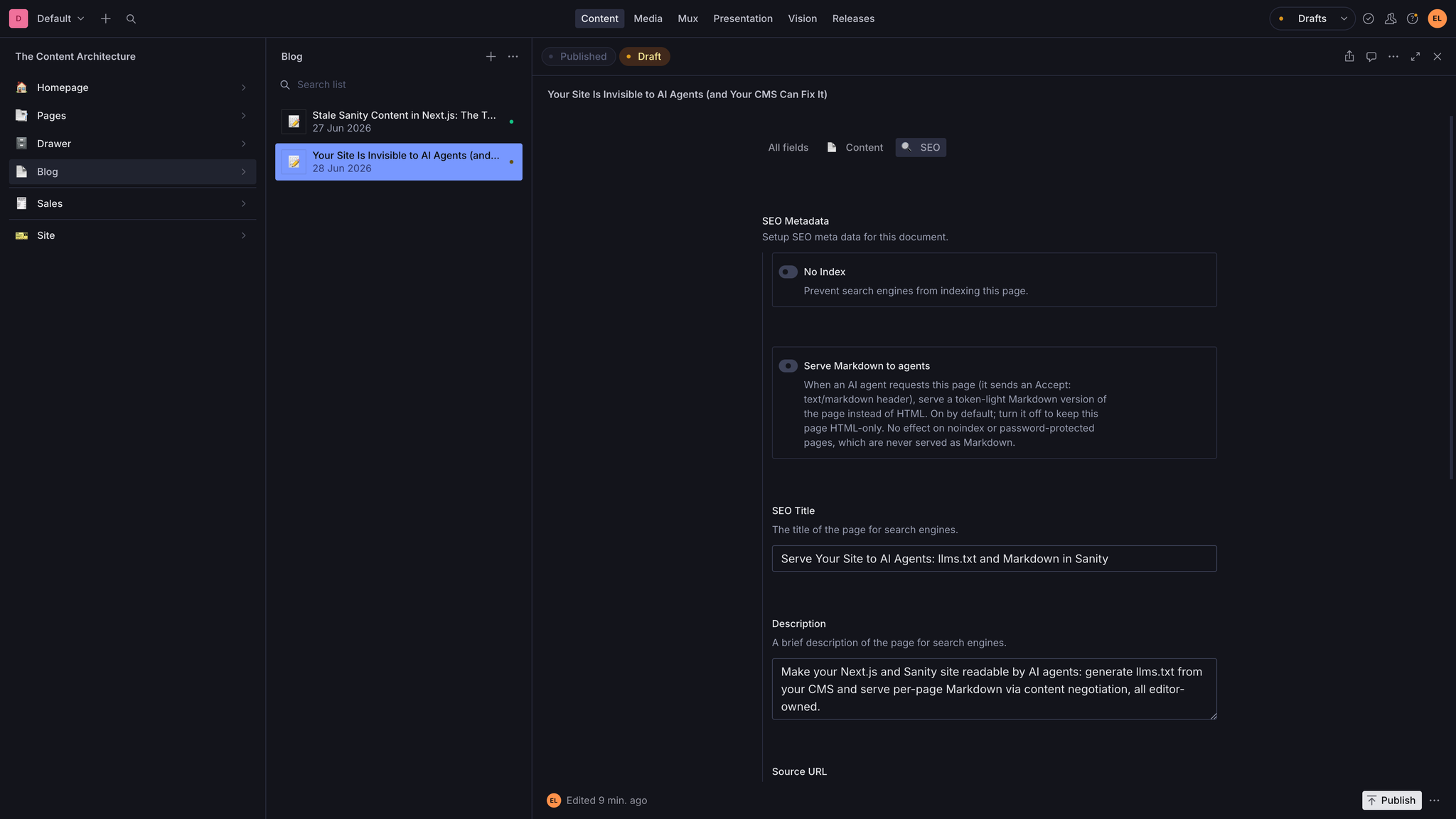
Retrieval: Markdown on the same URL
Accept header. A browser sends Accept: text/html,... and never lists Markdown, so it always gets HTML. An agent that sends Accept: text/markdown gets the Markdown. This is content negotiation, a part of HTTP that has existed for decades, used here to serve agents without giving them a separate set of URLs to discover. The /llms.txt index links your normal page URLs, and those same URLs answer in Markdown when an agent asks. The two features lock together with no extra wiring.Accept header never contains "markdown," so the check that detects an agent fails on the first character and the request continues down the normal HTML path with no added work. Every reader who is not an agent pays nothing. Only the rare agent request does the eligibility read, and that read is cached and busted by webhook, so even agents barely touch the database.The part that took three tries
appRichText. A media factory always produces appMedia. A link factory always produces appLink. Those names are guaranteed on any section built from the factories, so the serializer reads them wherever they appear and renders each to Markdown, with no per-section branching. A new section serializes the day it is created.How the two features combine
llms.txt. It reads the index, a map of real page URLs with descriptions an editor approved. It picks the page it needs and fetches that same URL with Accept: text/markdown. The page answers in lean Markdown, the body and nothing else, internal links resolved to absolute URLs so the agent can follow them deeper. The same URLs serve both halves, no special infrastructure between them. For agents that read the index but do not negotiate Markdown on their own, one line in the generation notes that every page is also available through the Accept header.Why this is a competitive line now, not later
public/ and watching it drift. The work is not large. The boundary is what is hard, and the boundary is what most implementations get wrong.llms.txt generator wired to Agent Actions, the per-page Markdown toggle, the factory-guaranteed serializer, the proxy that serves agents without taxing browsers. A client build starts with the agentic layer done, past the part that usually costs the first few days and gets cut for time anyway.Common questions
What is llms.txt and do I need it?
How do I generate llms.txt from a CMS instead of hardcoding it?
public/ drifts the moment anyone publishes. The stronger version stores the file in the CMS as an editor-owned field and drafts it with an AI action, so editors reword and reorder it without a deploy while the URLs stay grounded in code.How do I serve Markdown to AI agents from a Next.js site?
Accept: text/markdown header on incoming requests and return a Markdown version of the page on the same URL, while browsers asking for text/html get the normal page. This is HTTP content negotiation. Put the detection in the proxy so it can short-circuit browser traffic for free and consult per-page state, like whether the page is private or toggled off, before serving.For engineers building on the stack
The Content Architecture is the Next.js and Sanity foundation that ships with the agentic layer already wired. If you build on this stack, the list is where new patterns, deep dives, and product updates land first. No filler, just the engineering.